In this AWS re:Post Article, I walk through the troubleshooting process I went through trying to allow >5MB files to […]
A First Look at AWS CloudFormation IaC Generator
In this AWS re:Post Article, I demonstrate the brand new CloudFormation Infrastructure-as-Code feature, released in February 2024.
Using lifecycle_scope with vTGW/TGW peering in VMware Cloud on AWS
In this AWS re:Post Article, I demonstrate using a new feature in the AWS Terraform provider. The lifecycle scope feature […]
Testing Terraform Providers Written in Go
In this AWS re:Post Article, I describe how I test changes to the HCX provider for VMC On AWS.
A Go novice’s experience with Terraform providers
In this AWS re:Post Article, I explain how I added support for M1 Macs to an open source Terraform provider […]
Cloning a VM using pyVmomi in VMware Cloud on AWS
There are many ways to automate clone a virtual machine, including PowerCLI and the pyVmomi library for Python. In this […]
Using PowerCLI to import and export VMs with VMware Cloud on AWS
PowerCLI is commonly used by vSphere admins to automate tasks. In this AWS re:Post Article, I demonstrate importing and exporting […]
Automating the account linking process in VMware Cloud on AWS
In this AWS re:Post Article, I explore automating a typically manual process – linking a VMware Cloud on AWS org […]
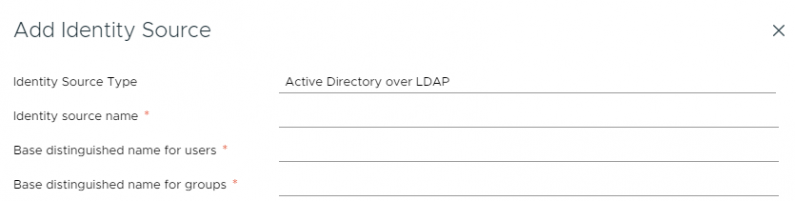
vCenter Roles with LDAP credentials in VMware Cloud on AWS
In this AWS re:Post Article, I demonstrate how to ensure your LDAP administrative users have the same permissions level as […]

My AWS Solution Architect Associate SAA-C03 exam experience
I sat the AWS-SAA C03 exam on June 23rd. Unlike the SAA-C02 exam that I took in 2020, I went […]