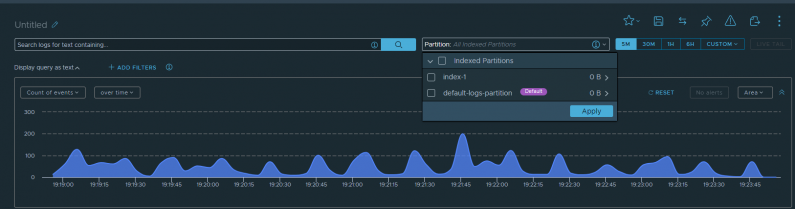
In this AWS re:Post Article, I cover a request that one of my customers had yesterday. They need to forward […]
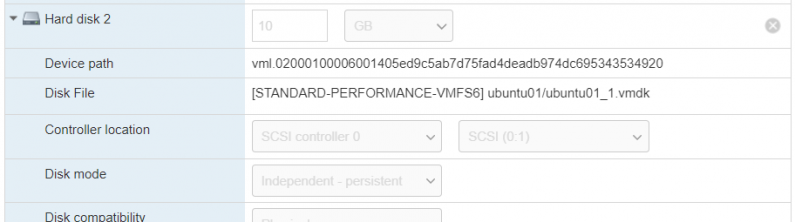
AWS Elastic Disaster Recovery with VMware Raw Device Mappings
In this re:Post Article, I demonstrate using AWS Elastic Disaster Recovery to fail over a filesystem backed by a physical […]

Holiday lighting automation with the Tuya IoT API
We do a lot of Halloween decorating at our house, both indoor and outdoor. My oldest son loves Halloween. Every […]
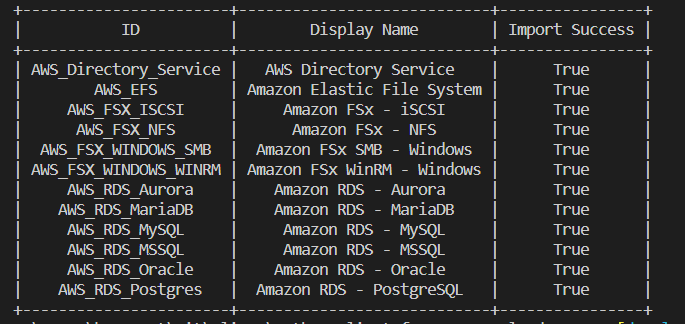
Custom service definitions in VMware Cloud on AWS
In this re:Post Article, I walk through a feature I contributed to the Python Client for VMware Cloud on AWS […]
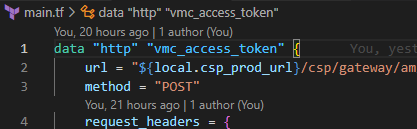
Invoking VMware Cloud on AWS REST API calls from Terraform
In this re:Post Article, I demonstrate invoking the VMC on AWS REST API from Terraform. There are often situations where […]
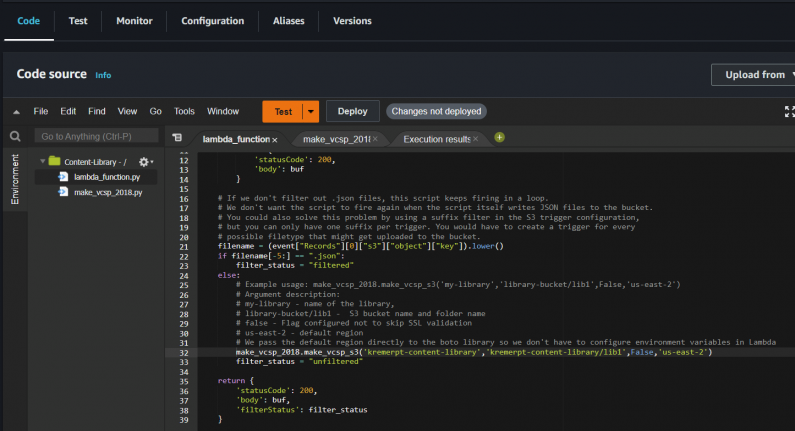
Automated S3 Content Library Indexing with AWS Lambda
Content libraries are container objects for VM and vApp templates and other types of files, such as ISO images. A […]
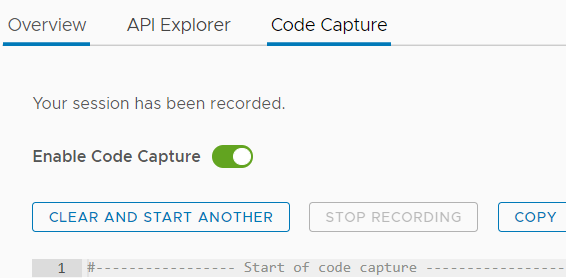
Using Code Capture to decipher VMware APIs
Now that I work at AWS, most of my content will be published on AWS-owned repositories. AWS re:Post is a […]

All Good Things…
As the proverb goes – all good things must come to an end. My last day at VMware was July […]
Stranger Things – Phones and VoIP.
We’re huge fans of Stranger Things in this house and we decided to decorate the basement for the second half […]
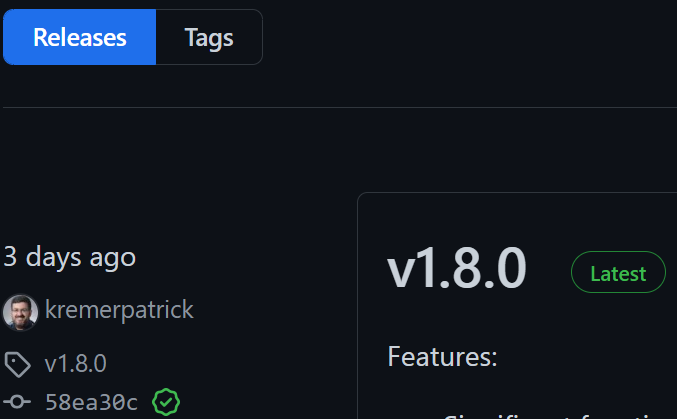
Python Client for VMC on AWS – Part IV – Release 1.8
It has been quite some time since we’ve had a PyVMC release. We published v1.8 on May 20th, 2022. The […]