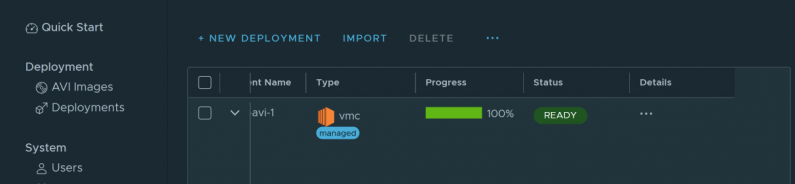
In Part I of this series, we deployed NSX Advanced Load Balancer resources with the Easy Deploy Fling. In this post, we will look at the resources that have been deployed.
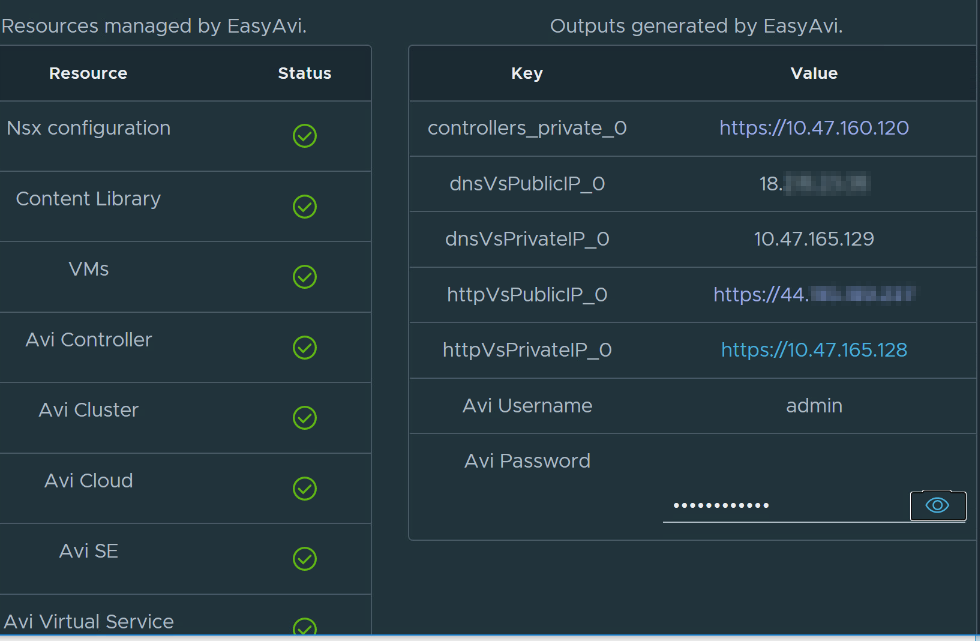
The deployment shows all of the managed EasyAvi resources, as well as IPs.
Sample Application
The Fling deployed a sample application for us. It gives us the public IP address (https://44.x.x.x). We browse to the IP and the browser shows:

If we hit refresh, the browser shows:
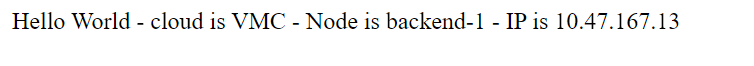
Repeated refreshes bounce back and forth between the 2 nodes – so we know that the load balancer is deployed in a round-robin configuration.
Looing at the SDDC NAT configuration, we see a NAT in place to the VIP of 10.47.165.128, which matches the http private IP shown above.

If we browse to the private VIP, the we see the same round-robin behavior.


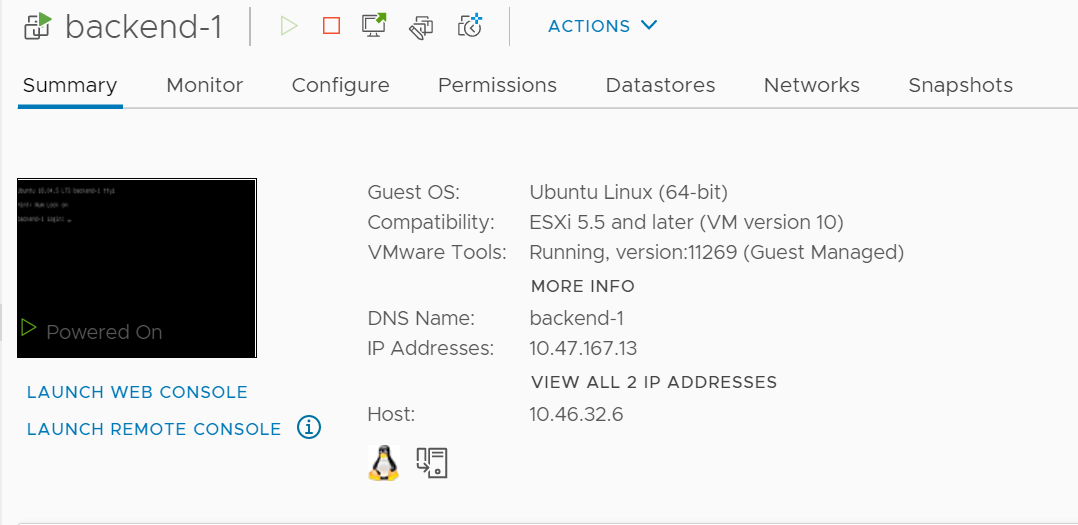
In vCenter, I find two VMs matching those private IPs – backend-0 and backend-1

Log into the Controller
The deployment gives us the private IP of the controller – 10.47.160.120, as well as the username (admin) and the password.
We browse to the IP and log in with the credenials.
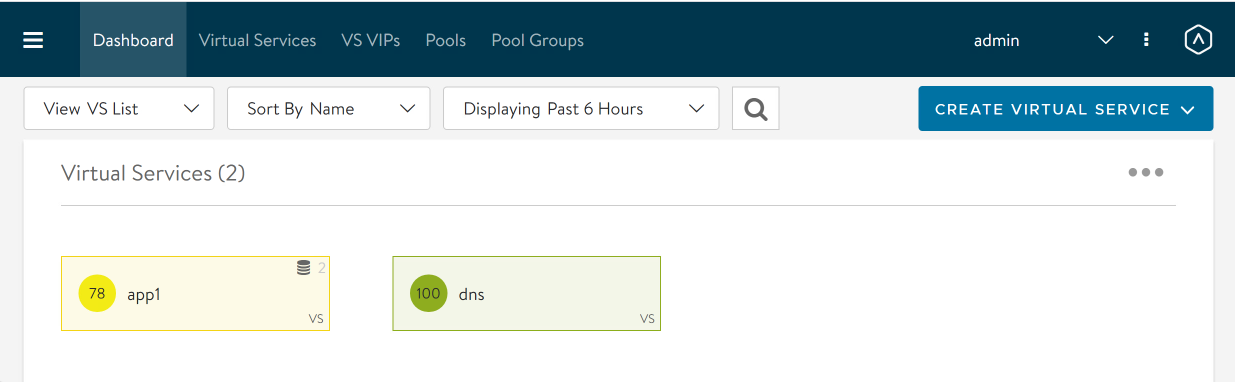
The dashboard shows us 2 virtual services. Let’s check out app1. It doesn’t look particularly healthy
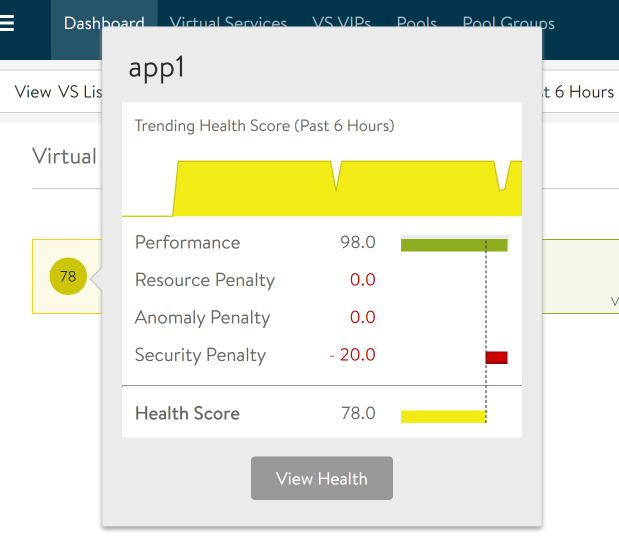
Hover the mouse over the health score (78). We see we are being docked 20 points for a security penalty. Click on View Health.
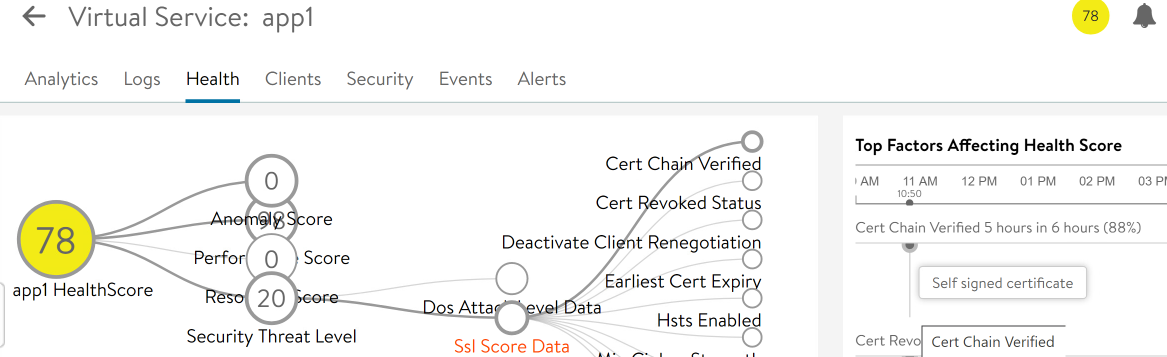
Click on the 78 for Health Score, then the 20 Security Threat Level, then the SSL Score Data. We see we the problem is that the cert chain is not verified because we are using a self-signed cert.
Click the edit pencil on the right

Scroll down toward the bottom, looking for Service Port
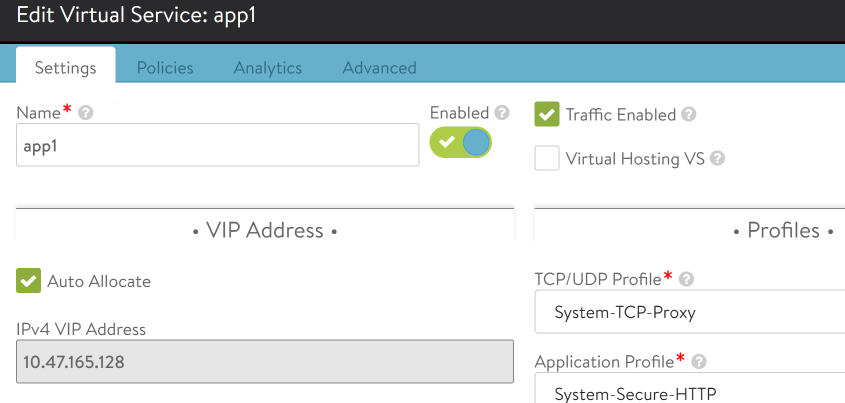
Here we find that port 443 is load balanced into pool pool1-hello-vmc. Click cancel.
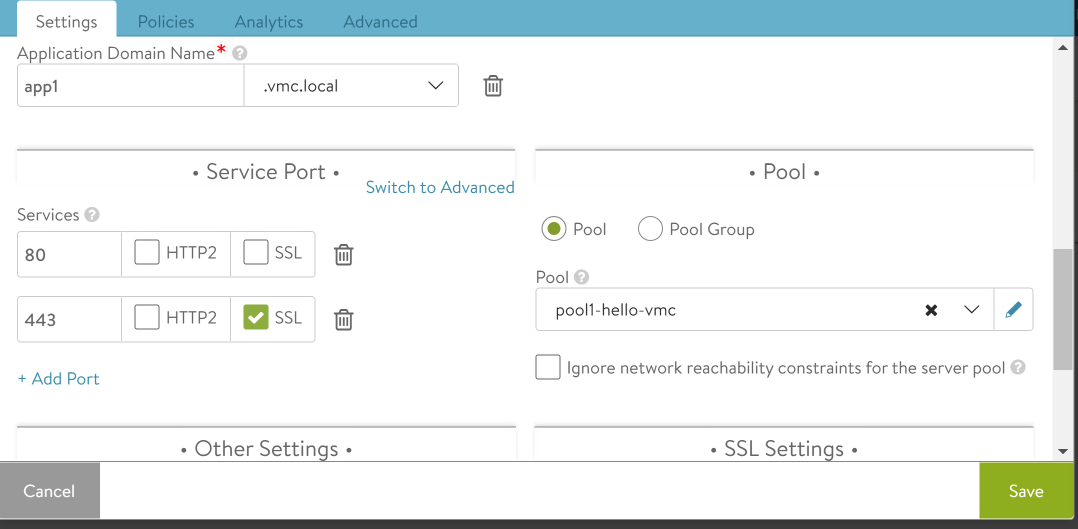
Click the pencil to edit pool1-hello-vmc
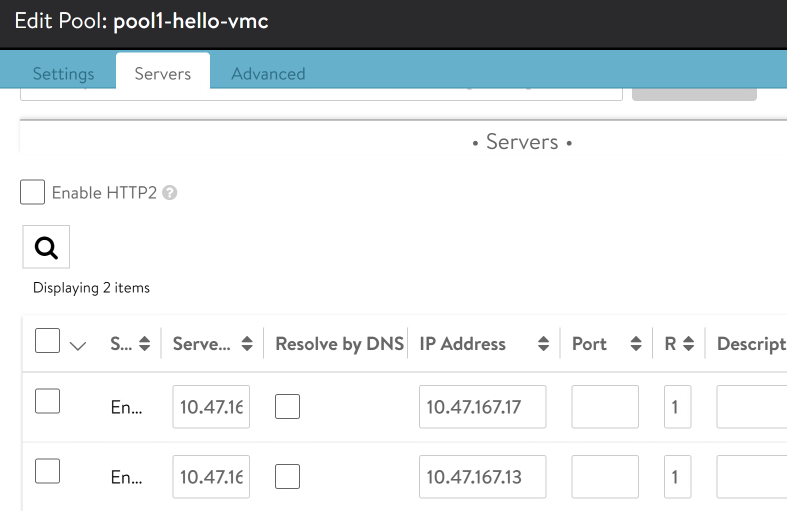
On the Servers tab, we find the two node IPs that we are expecting from our browser tests above – 10.47.167.13 and 10.47.167.17.
Testing Failure
Let’s see what happens if we shut down backend-0
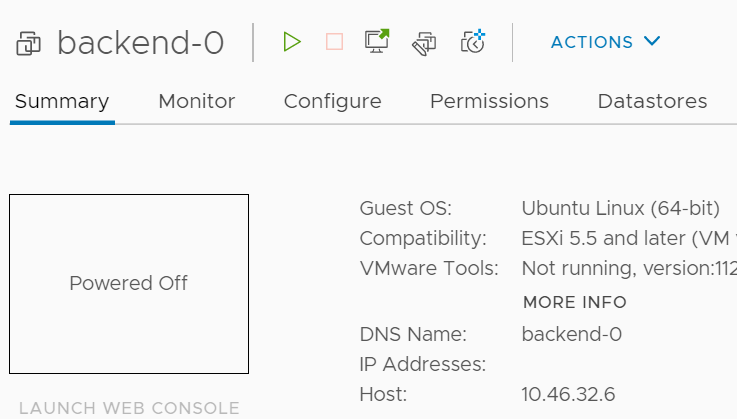
All nodes remain healthy.
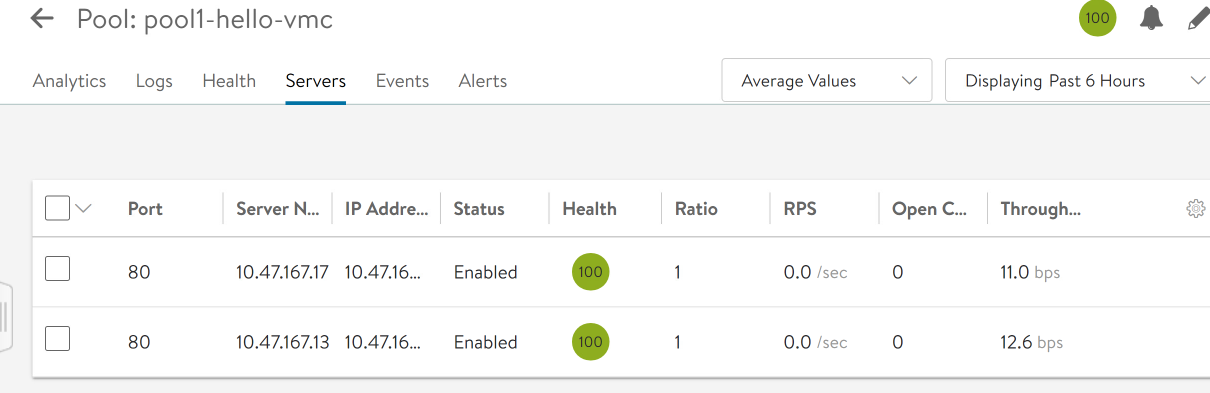
Connections to backend-1 succeed. But every time the connection goes to backend-0, the browser hangs.

Eventually we get an error 503.

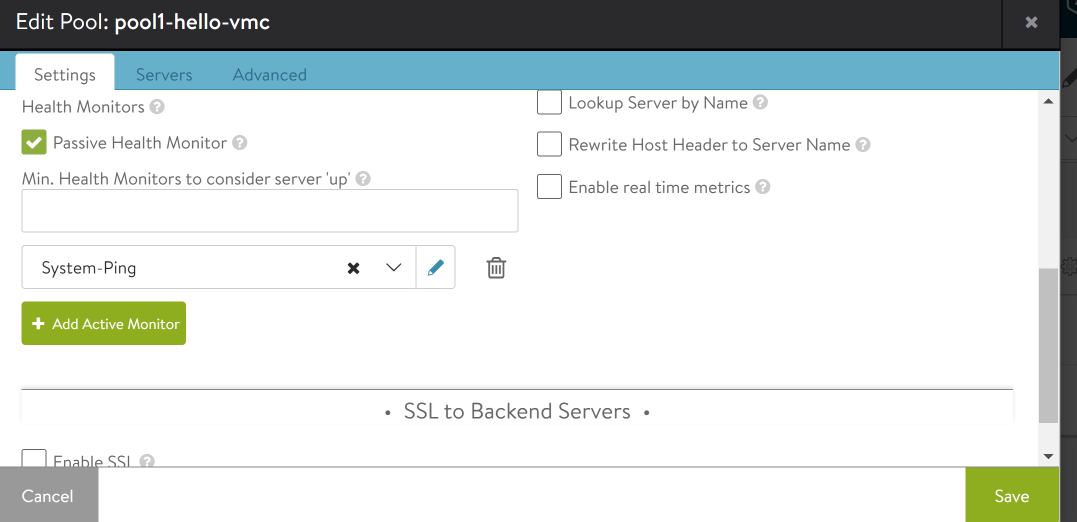
The reason the load balancer isn’t taking the node out of service is because we only have Passive health monitors enabled. You can learn more about Passive monitors here. Let’s try to add an active ping monitor – it’s not as good as an HTTP monitor, but it’s better than the passive monitor we have. Click Add Active Monitor

Click the down arrow next to Select a Health Monitor
Select System-Ping
Click Save
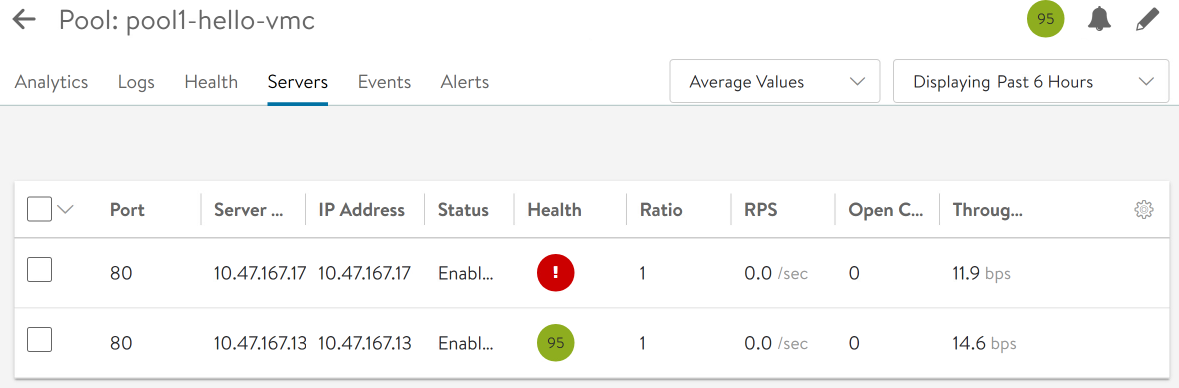
The powered-down backend-0 node gets marked out of service.
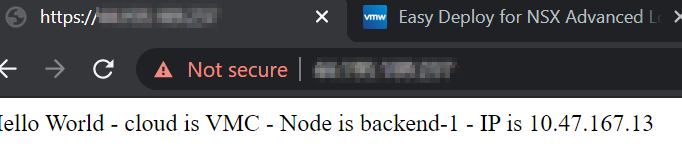
On every refresh we now get backend-1.
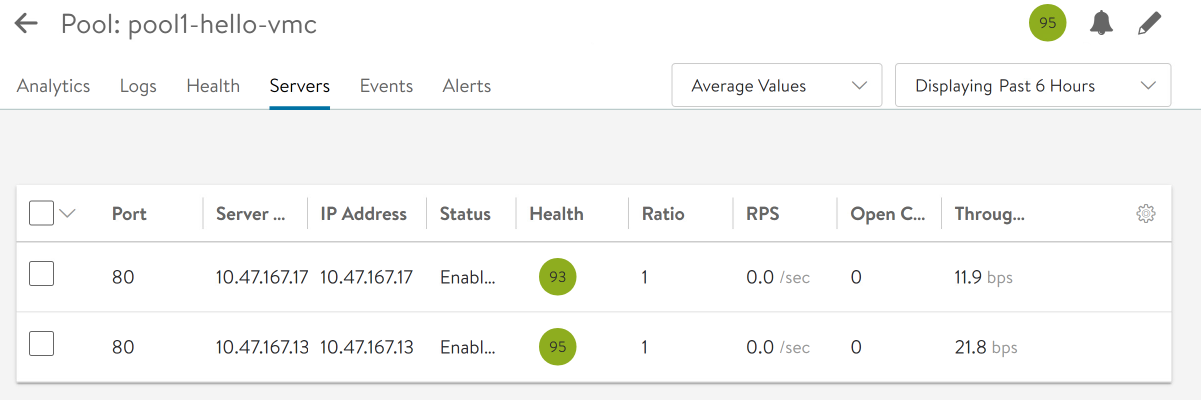
We power up backend-0. The node comes back into service, and we go back to round-robin load balancing between the 2 nodes.
That’s all for this post. In the next post, we will add an active HTTP monitor.
NSX Advanced Load Balancer – Part III – Active HTTP Monitor -
[…] Part II of this series, we looked at some of the resources that Easy Deploy built for us, including the […]
NSX Advanced Load Balancer - Part I - Installation with Easy Deploy -
[…] the next post, we will explore the load balancer services configured by the […]